福布斯系列(5)-数据清洗(a)
阅读量:次 Authors: Lemon PROJECTS
projects-forbes Pandas Numpy
阅读量:次 Authors: Lemon PROJECTS
projects-forbes Pandas Numpy
Table of Contents
福布斯系列之数据清洗(1) - Python数据分析项目实战
本文作为数据清洗的第一篇,将详细的描述福布斯全球上市企业2000强排行榜数据中2007年数据的处理过程。
通常,我们都希望自己拿到的数据是比较规范,看起来令人清爽的数据。
然而,实际上我们获得的信息或数据,会因为各种各样的原因,存在数据缺失、不准确、不规范等异常情况。
需要我们在进行数据分析之前进行预处理。
福布斯全球上市企业2000强排行榜数据,从2007年到2017年,各个年份的数据都存在一些不规范的地方。
从本文开始至接下来的几篇文章,将通过福布斯项目来进行数据清洗的项目实战,希望能给大家带来些收获。
本项目运行环境:
将不规范的数据进行处理,包括:
最终达到的效果如下:
数据清洗前
数据类型
年份 int64
排名(Rank) int64
公司名称(Company) object
所在国家或地区(Country) object
所在行业(Industry) object
销售收入(Sales) object
利润(Profits) object
总资产(Assets) object
市值(Market Vaue) float64
dtype: object
图1:

数据清洗后
数据类型
Year int64
Rank int64
Company_cn_en object
Company_en object
Company_cn object
Country_cn_en object
Country_cn object
Country_en object
Industry_cn object
Industry_en object
Sales float64
Profits float64
Assets float64
Market_value float64
dtype: object
图2:

数据清洗后, sales、Profits、Assets及Market_value列的数据均为数字类型,方便后续分析时计算使用。
import pandas as pd
import numpy as np
2007年的数据,原始数据的单位为十亿美元。
df_2007 = pd.read_csv('./data/data_forbes_2007.csv', encoding='gbk', thousands=',')
print('the shape of DataFrame: ', df_2007.shape)
print(df_2007.dtypes)
df_2007.head(3)
out:
the shape of DataFrame: (2000, 9)
年份 int64
排名(Rank) int64
公司名称(Company) object
所在国家或地区(Country) object
所在行业(Industry) object
销售收入(Sales) object
利润(Profits) object
总资产(Assets) object
市值(Market Vaue) float64
dtype: object
图1:
更新columns的命名
column_update = ['Year', 'Rank', 'Company_cn_en', 'Country_cn_en',
'Industry_cn', 'Sales', 'Profits', 'Assets', 'Market_value']
df_2007.columns = column_update
图3:

通过前面的分析可看出,只有“Market_value”是数字类型,找出’Sales’,’Profits’及’Assets’中非数字的内容
df_2007[df_2007['Sales'].str.contains('.*[A-Za-z]', regex=True)]
图4:

用replace()方法替换“Sales”列中含有字母的内容
df_2007['Sales'] = df_2007['Sales'].replace('([A-Za-z])', '', regex=True)
查看替换后的结果
df_2007.loc[[117,616,880], :]
图5:

查看“Assets”列中非数字的内容
df_2007[df_2007['Assets'].str.contains('.*[A-Za-z]', regex=True)]
图6:

替换非数字的内容,以及替换千分位间隔符号
# 将数字后面的字母进行替换
df_2007['Assets'] = df_2007['Assets'].replace('([A-Za-z])', '', regex=True)
# 千分位数字的逗号被识别为string了,需要替换
df_2007['Assets'] = df_2007['Assets'].replace(',', '', regex=True)
df_2007.loc[616, :]
out:
Year 2007
Rank 617
Company_cn_en Inpex Holdings
Country_cn_en 日本(JA)
Industry_cn 炼油
Sales 6.49
Profits 1.02 E
Assets 10.77
Market_value 19.65
Name: 616, dtype: object
发现“Profits”中有NaN值,需要先进行替换
df_2007[pd.isnull(df_2007['Profits'])]
# 将NaN值替换为0
df_2007['Profits'].fillna(0, inplace=True)
df_2007.loc[[958,1440,1544,1912], :]
图7-8:
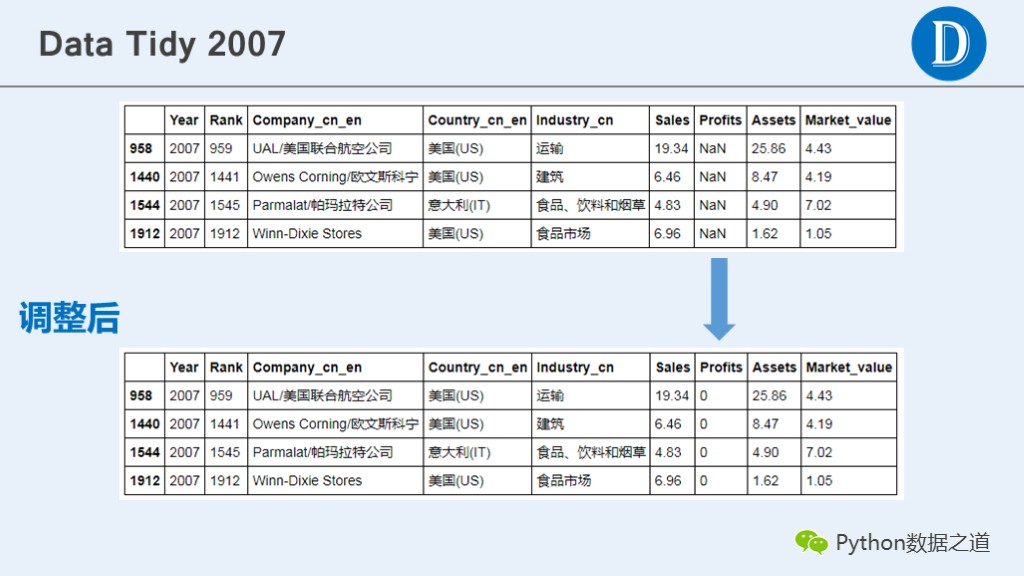
将“Profits”列中非数字的内容进行替换,并查看替换后的结果
df_2007['Profits'] = df_2007['Profits'].replace('([A-Za-z])', '', regex=True)
df_2007.loc[[117,616,880], :]
图9:

将string类型的数字转换为数据类型,这里使用 pd.to_numeric() 方法
df_2007['Sales'] = pd.to_numeric(df_2007['Sales'])
df_2007['Profits'] = pd.to_numeric(df_2007['Profits'])
df_2007['Assets'] = pd.to_numeric(df_2007['Assets'])
df_2007.dtypes
out:
Year int64
Rank int64
Company_cn_en object
Country_cn_en object
Industry_cn object
Sales float64
Profits float64
Assets float64
Market_value float64
dtype: object
新生成两列,分别为公司英文名称和中文名称
df_2007['Company_en'],df_2007['Company_cn'] = df_2007['Company_cn_en'].str.split('/', 1).str
print(df_2007['Company_en'][:5])
print(df_2007['Company_cn'] [-5:])
df_2007.tail(3)
out:
0 Citigroup
1 Bank of America
2 HSBC Holdings
3 General Electric
4 JPMorgan Chase
Name: Company_en, dtype: object
1995 NaN
1996 NaN
1997 NaN
1998 NaN
1999 NaN
Name: Company_cn, dtype: object
图10:

新生成两列,分别为国家中文名称和英文名称
df_2007['Country_cn'],df_2007['Country_en'] = df_2007['Country_cn_en'].str.split('(', 1).str
print(df_2007['Country_cn'][:5])
print(df_2007['Country_en'][-5:])
out:
0 美国
1 美国
2 英国
3 美国
4 美国
Name: Country_cn, dtype: object
1995 US)
1996 US)
1997 US)
1998 SI)
1999 GE)
Name: Country_en, dtype: object
由于国家的英文名称中,最后有半个括号,需要去除,用 Series.str.slice()方法
参数表示选取从开始到倒数第二个,即不要括号”)”
df_2007['Country_en'] = df_2007['Country_en'].str.slice(0,-1)
df_2007.head(3)
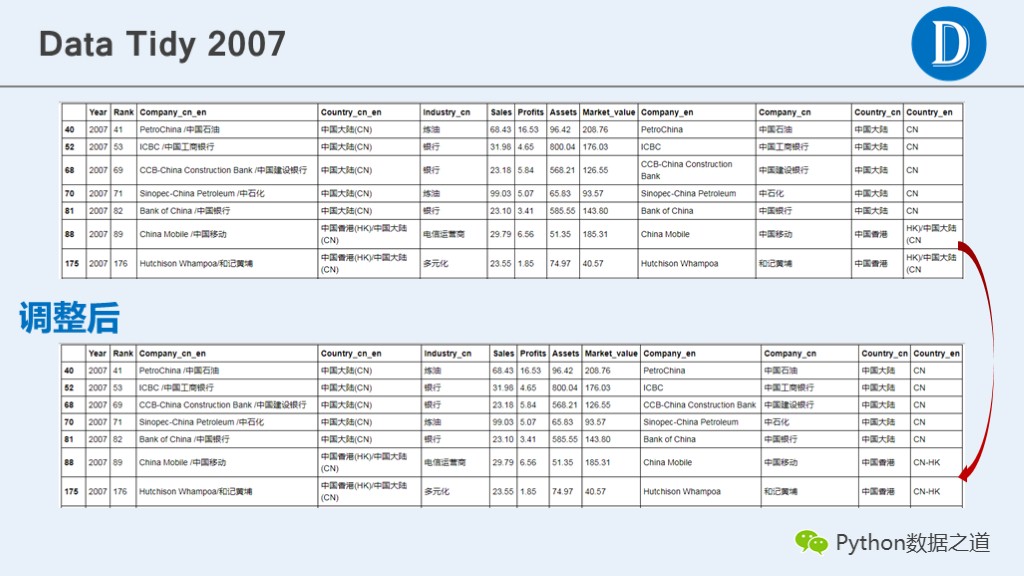
考虑的中国的企业有区分为中国大陆,中国香港,中国台湾。
对应的国家英文名称也需要修改下。
# 查找含“中国”的数据
df_2007[df_2007['Country_cn'].str.contains('中国',regex=True)]
# 替换并查看结果
df_2007['Country_en'] = df_2007['Country_en'].replace(['HK.*','TA'],['CN-HK', 'CN-TA'],regex=True)
df_2007[df_2007['Country_en'].str.contains('CN',regex=True)]
图11-12:
考虑到其他年份,公司所在行业有用英文名称展示的,这里添加一列英文的行业名称,但内容是空白
df_2007['Industry_en'] = ''
df_2007.tail(3)
columns_sort = ['Year', 'Rank', 'Company_cn_en','Company_en',
'Company_cn', 'Country_cn_en', 'Country_cn',
'Country_en', 'Industry_cn', 'Industry_en',
'Sales', 'Profits', 'Assets', 'Market_value']
# 按指定list重新将columns进行排序
df_2007 = df_2007.reindex(columns=columns_sort)
print(df_2007.shape)
print(df_2007.dtypes)
df_2007.head(3)
out:
(2000, 14)
Year int64
Rank int64
Company_cn_en object
Company_en object
Company_cn object
Country_cn_en object
Country_cn object
Country_en object
Industry_cn object
Industry_en object
Sales float64
Profits float64
Assets float64
Market_value float64
dtype: object
图result:
至此,将2007年的原始数据进行了初步处理,当然,在后续的分析过程中,可能还会有少量的处理。
经过数据清洗后,获得的数据信息相对来说比较规范,数据的质量较好,可以用来后续分析使用或者进一步清洗。
数据清洗是数据分析、数据挖掘中一项基本且非常重要的技能,通过在整个数据分析中所用时间的比例会比较高。
当然,本次数据清洗的过程,还有可以优化的地方,各位同学可以自行研究下。
关注微信公众号公众号”Python数据之道”,后台回复”2017038“,获取本文的源代码及原始数据文件。
