福布斯系列(3)-数据完整性检查
阅读量:次 Authors: Lemon PROJECTS
projects-forbes Pandas
阅读量:次 Authors: Lemon PROJECTS
projects-forbes Pandas
Table of Contents
福布斯系列之数据完整性检查 - Python数据分析项目实战
用Python进行数据分析项目实战之福布斯系列文章,目前已发布的相关文章如下:
在上篇文章中,介绍了使用python爬取福布斯全球上市企业2000强排行榜(Forbes Global 2000)数据的思路和步骤。
在获取数据后,首先需要对获得的数据的完整性情况进行检查,主要查看数据是否有缺失、是否有重复、是否有数据错位或其他异常情况。
数据完整性检查也包括不同数据来源的对比,以及其他一些常识性的知识。
当然,在拿到数据的初期,其实只能做一个初步的判断,有些内容是在整个分析过程中发现的。
福布斯全球上市企业2000强排行榜,企业数量应该是2000家,或者稍微多几家(因为排名可能相同,会增加少量企业)。
所以首先需要检查这个排行榜上每年的企业数量,如果明显多余2000家或者少于2000家企业,则说明获得的数据可能异常。
在使用Python分析时,可以用Pandas来进行检查,使用DataFrame.shape就可以查看企业数量。
下面以2007年的数据为例来介绍。 代码如下:
df_2007 = pd.read_csv('./data/data_forbes_2007.csv', encoding='gbk', thousands=',')
print('the shape of DataFrame: ', df_2007.shape)
out:
the shape of DataFrame: (2000, 9)
从运行结果可以看出,2007年的企业数量是2000家,是符合要求的。
用同样的方法,逐个检查其他年份,发现2013年和2015年的企业数量有异常。
通过查看,发现 2013年的企业数量只有1991家,少于2000家。
df_2013 = pd.read_csv('./data/data_forbes_2013.csv', encoding='gbk',header=None)
print('the shape of DataFrame: ', df_2013.shape)
out:
the shape of DataFrame: (1991, 9)
同时,2015年的企业数量为2020家,明显多余2000家,可能有重复的内容。
df_2015 = pd.read_csv('./data/data_forbes_2015.csv', encoding='gbk',header=None)
print('the shape of DataFrame: ', df_2015.shape)
out:
the shape of DataFrame: (2020, 9)
上述的这些问题,都需要在后续的数据清洗、分析中进一步处理。
通过查看csv数据文件以及目标网页等文件,发现有部分数据错位或缺失等情况,需要分别处理。
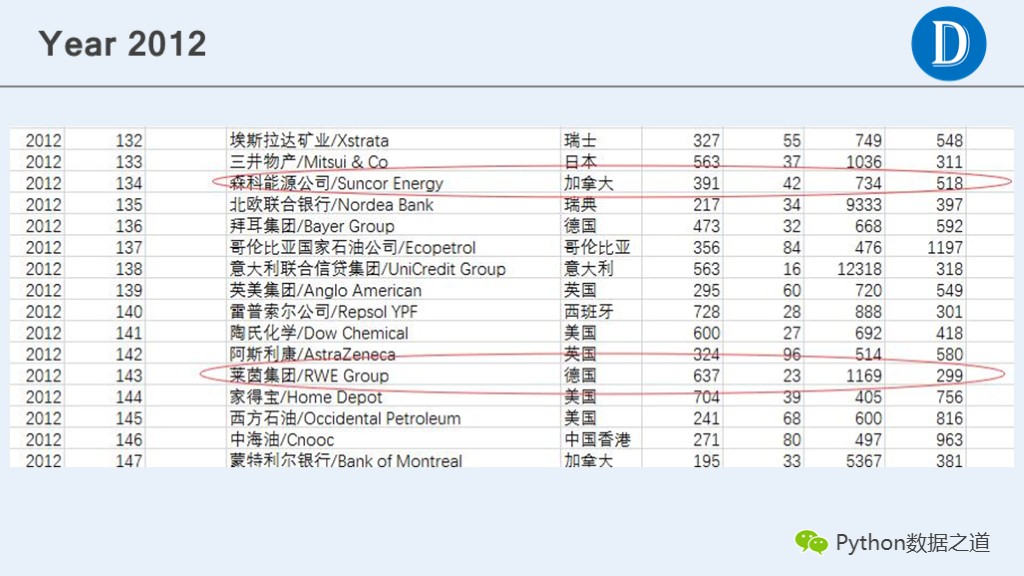
通过检查发现,2012年和2014年的数据有错位的现象,通过手动在csv文件中进行调整相关数据,以便在后续分析中继续使用这些数据。
2012年的情况
原始数据如下:
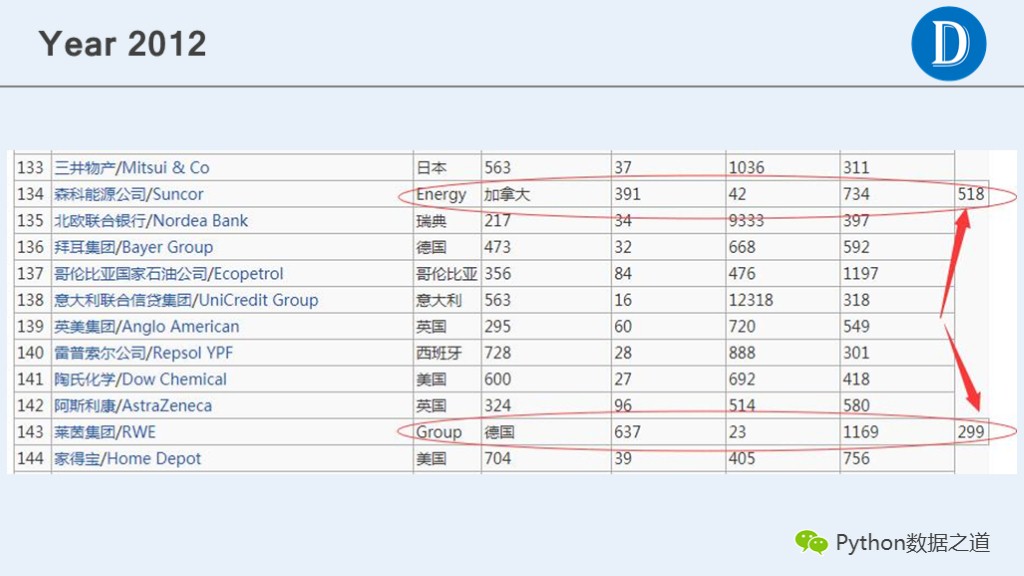
调整后的csv文件如下:
2014年的情况
原始数据以及调整后的csv文件如下:
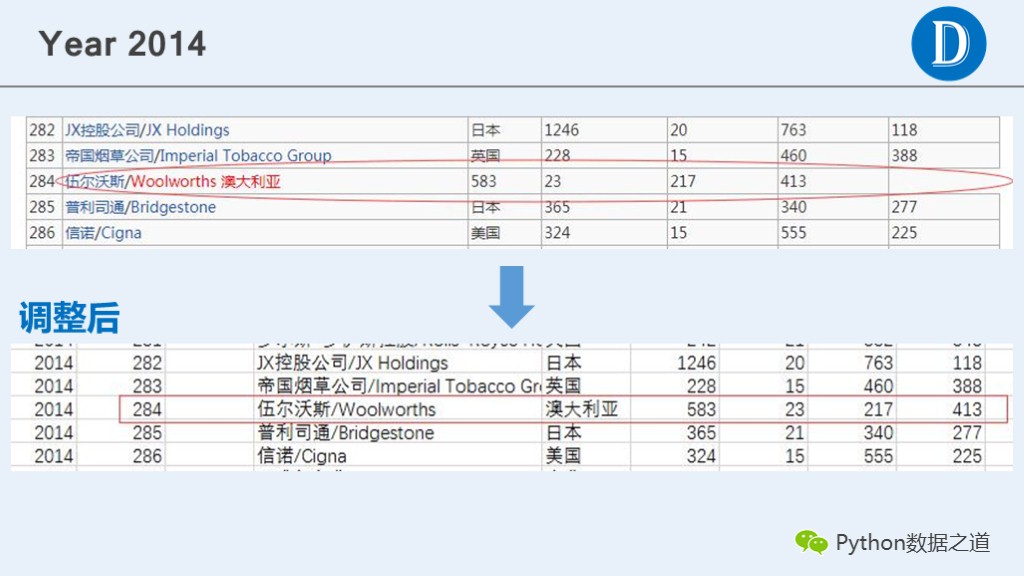
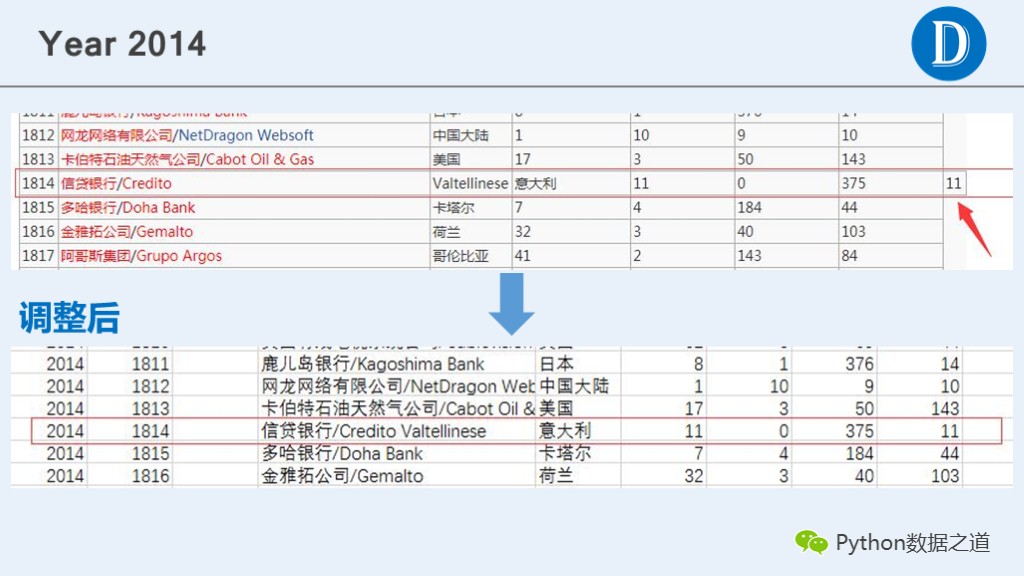
通过检查发现,2016年的数据有缺失的现象,通过查找其他信息,发现其他网站有完整的信息。
对比网站的数据,进行了手动修改。用来对比的网站信息如下:
http://www.askci.com/news/finance/20160530/13364822511_7.shtml
通过手动在csv文件中进行调整相关数据,以便在后续分析中继续使用这些数据。
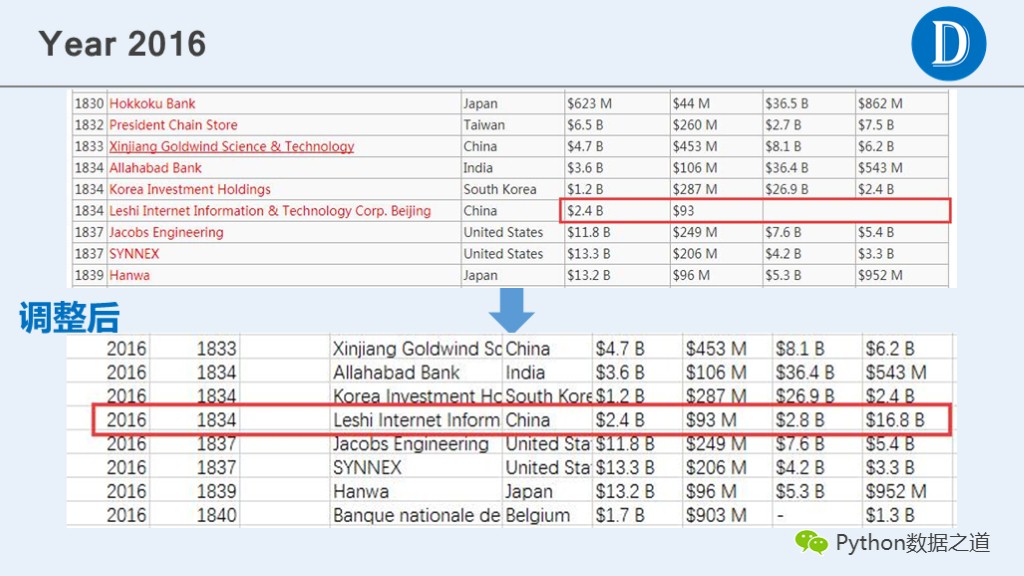
本次数据完整性检查主要包括企业数量是否完整,以及相关数据是否缺失、错位等情况的检查。
当然,有可能还有其他问题暂时没有发现,在后续数据清洗以及分析过程中,若发现有相关问题,可以进一步处理。
步骤1中发现的问题,将在福布斯系列的后续文章中进一步介绍如何解决这些问题,敬请持续关注。
对我的文章感兴趣的朋友,可以关注我的微信公众号”Python数据之道”,接收我的更新通知…….
