用 Python 读取巴菲特最近的持仓数据
阅读量:次 Authors: 阳哥 PYFINANCE
BeautifulSoup Pandas
阅读量:次 Authors: 阳哥 PYFINANCE
BeautifulSoup Pandas
Table of Contents
大家好,我是阳哥 ,最近关注巴菲特的同学比较多,结合2020年巴菲特致股东信,我也去了解了下伯克希尔最近的持仓情况 。
持仓情况的披露文件发布在美国证监会网站上,在美国, 13F 文件是机构公布季度持仓时需要披露的文件。
这个文件可能跟国内的有点不一样,我们一起来看看吧。
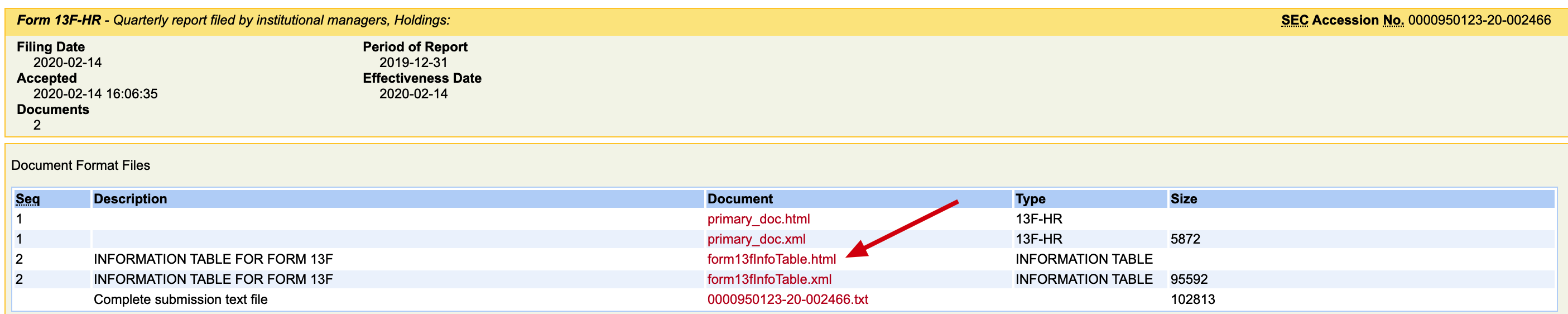
在官方网站上,是以网页格式进行披露的(html和xml),点击上图中红色箭头所指的 “html” 文件后,在会在网页格式中打开持仓情况。如下:
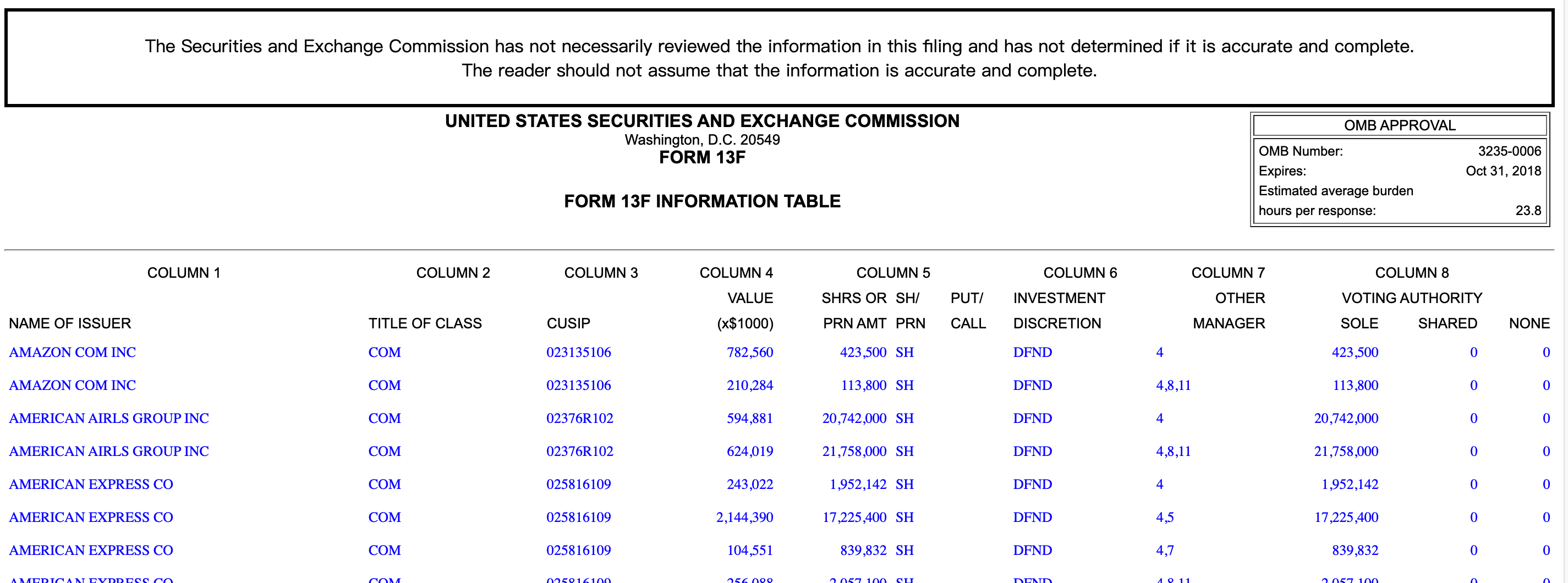
从上面的表格中,可以清晰的看出伯克希尔的持仓情况。如果我们想对伯克希尔的持仓情况进行分析,则可以将数据保存到本地,然后进行分析,尤其是涉及多份数据进行对比和分析的时候,对这些数据的读取和梳理就有必要了。
下面我们来看看如何用 Python 进行读取。首先,我们将下面红色箭头所指的 “xml” 文件下载到本地,名称为 “test.xml” 。

初步观察网页格式上的数据,可以看出,这个数据表格是一个嵌套型的表格,我们在数据分析的时候,最好进行转化为 二维的 dataframe 。
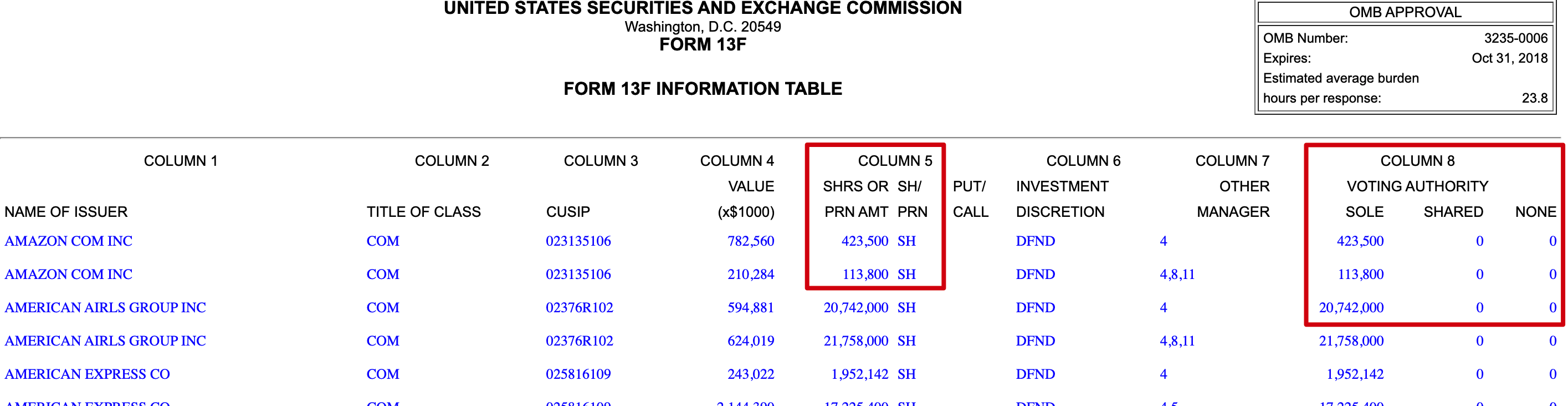
本来我是想用 Pandas 直接进行数据读取的,后来发现是 嵌套表格之后,有点麻烦。 于是改用 BeautifulSoup 来读取,可以将嵌套的数据也单独提取出来,方便后续分析。
用 BeautifulSoup 进行解析的时候,思路其实比较简单:
我们知道, BeautifulSoup 可以用来解析 html、xml 等网页的标记语言内容。因此,对于 XML 文件,我们可以直接进行读取。
下面的代码中的 “test.xml” 文件是我们保存的本地的文件,在本文结尾处也提供了获取方式。
# -*- coding: utf-8 -*-
"""
@Author: 阳哥
@出品:Python数据之道
@Homepage: liyangbit.com
"""
from bs4 import BeautifulSoup
import pandas as pd
path = r'./test.xml'
htmlfile = open(path, encoding='utf-8')
htmlhandle = htmlfile.read()
soup = BeautifulSoup(htmlhandle, 'xml')
print(soup)
读取标记语言的内容后,我们再来通过 BeautifulSoup 的 find_all 和 find 功能来读取所需要的数据即可。
对数据进行封装和保存的方法有多种,我们这里采取的是构造一个空的 Pandas 的 DataFrame 来进行封装,然后用 Pandas 的 to_excel 来保存文件,这种方法还是比较方便的,有兴趣的同学可以研究下。
count = 0
# 构造一个空的 dataframe
result = pd.DataFrame({}, index=[0])
# 根据持仓数据表格,添加需要保存的字段(dataframe 的 列名称)
result['nameOfIssuer'] = ''
result['titleOfClass'] = ''
result['cusip'] = ''
result['value'] = ''
result['sshPrnamt'] = ''
result['sshPrnamtType'] = ''
result['investmentDiscretion'] = ''
result['otherManager'] = ''
result['votingAuthority-Sole'] = ''
result['votingAuthority-Share'] = ''
result['votingAuthority-None'] = ''
new = result
for item in soup.find_all('infoTable'):
nameOfIssuer = item.find('nameOfIssuer').get_text()
new['nameOfIssuer'] = nameOfIssuer
titleOfClass = item.find('titleOfClass').get_text()
new['titleOfClass'] = titleOfClass
cusip = item.find('cusip').get_text()
new['cusip'] = cusip
value = item.find('value').get_text()
new['value'] = value
sshPrnamt = item.find('shrsOrPrnAmt').find('sshPrnamt').get_text()
new['sshPrnamt'] = sshPrnamt
sshPrnamtType = item.find('shrsOrPrnAmt').find('sshPrnamtType').get_text()
new['sshPrnamtType'] = sshPrnamtType
investmentDiscretion = item.find('investmentDiscretion').get_text()
new['investmentDiscretion'] = investmentDiscretion
otherManager = item.find('otherManager').get_text()
new['otherManager'] = otherManager
Sole = item.find('votingAuthority').find('Sole').get_text()
new['votingAuthority-Sole'] = Sole
Shared = item.find('votingAuthority').find('Shared').get_text()
new['votingAuthority-Share'] = Shared
Non = item.find('votingAuthority').find('None').get_text()
new['votingAuthority-None'] = Non
count += 1
result = result.append(new, ignore_index=True)
print(count)
print(result)
# 保存数据到 Excel 表格
result.to_excel('BRKA-2019-Q4.xlsx')
如果后续需要对数据进行分析和可视化,可以借助 Pandas、Matplotlib、Plotly 等 Python 库来处理。
当然,如果你只是想看看或分析这一份文件,也可以直接从网页上复制内容到 Excel 表格中即可,获取数据的方法有多种,选择适合自己的就好哈。
最后,为方便大家进行操作,Lemonbit 给大家提供了 源代码和数据文件,可以在公众号「Python数据之道」后台回复数字 「690」进行获取。
对我的文章感兴趣的朋友,可以关注我的微信公众号「Python数据之道」(ID:PyDataLab),接收我的更新通知。
