12条经验,让你在机器学习的路上避免很多坑
阅读量:次 Authors: 阳哥 MACHINELEARNING
MachineLearning
阅读量:次 Authors: 阳哥 MACHINELEARNING
MachineLearning
Table of Contents
成为你自己最大的怀疑者,挖掘那些可能不起作用的事情的价值,以及探索沟通问题比技术问题更困难的原因。 Being your own biggest sceptic, the value in trying things which might not work and why communication problems are harder than technical problems.
作者:Daniel Bourke
翻译:李洁
整理:阳哥
译文出品:Python数据之道

工作站,家庭办公室和艺术工作室。本文原作者提供的照片
机器学习和数据科学都是广义的术语。一个数据科学家所做的工作可能与另一个大不相同。机器学习工程师也是如此。常见的是使用过去(的数据)来理解或预测(建模)未来。
为了让以下观点拥有清晰的语境,我将先阐述一下我的工作。
我们曾有一个小型的机器学习咨询团队。我们在你能想到的每一个行业,做了所有从数据收集到操作,从模型构建到服务部署的工作。所以每个人都有许多头衔。
过去时态是因为我已经离开了机器学习工程师的职位,开始自己创业。我做了一个相关视频 https://youtu.be/a-IYqSw5ISs。
早上 9 点,我会走进来,说个早上好,把食物放进冰箱,倒杯饮料,走到我的办公桌前。然后我会坐下来,看看前一天的笔记,放松一下。我会阅读消息,打开团队分享的论文或博客文章的链接,会有一些有用内容,这个领域发展很快。
一旦把消息打理完毕,我就会快速浏览那些论文和博客文章,并详细阅读那些遇到困难的地方。通常会有一些对我所做的工作有所帮助的内容。阅读时间长达一个小时,有时更长,取决于阅读的内容。
为什么需要这么长时间?
阅读是终极的元技能,如果有更好的方法来做我正在做的事情,我愿意通过学习和实现它来节省时间和精力。
现在是上午 10 点。
如果接近某个最后期限,阅读时间将被缩短,以推进项目。这是一天中最重要的部分。我会回顾前一天的工作,检查我的记事本,看看我下一步该怎么做。
我的记事本是一天内的流水日志。
“我已经将数据处理成了正确的形状,现在我需要投入模型训练,我将在开始时缩短训练时间,然后如果取得进展,就加快训练进度。”
如果我陷入困难。
“一旦发生了数据不匹配,下一步将是进行修复,并在尝试新模型之前获取基准线情景。”
大部分时间都是在确保数据的形式可以建模。
下午 4 点左右,是时候开始整理了。收尾工作包括清理我为使代码清晰易读而创建的混乱代码,添加注释并重组代码。如果别人需要读这个代码呢?这就是我要问的问题。通常是我自己来读。令人惊讶的是一系列的想法竟然很快就会被遗忘。
到下午 5 点,我会把代码提交到 Github 上,将为下一天所做的笔记整理到我的记事本上。
这是理想中的一天,但不是每天都是这样。有时候你会在下午 4 点 37 分脑袋里突然出现一个好的想法,然后就开始着手去做。
现在你已经对每天会发生的事情有了大致的了解,我们将具体说明。
如果你熟悉一些数据科学的首要原则,那么这似乎是老生常谈。但令人惊讶的是,我经常会忘记。很多时候,你会把注意力集中在建立一个更好的模型上,而不是改进你所建立在的数据上。
构建一个更大的模型并使用更多的计算能力可以提供令人兴奋的短期结果。然而,走再多的捷径,最终也会需要长途跋涉。
当第一次参与一个项目时,你需要花大量的时间熟悉数据。我举一个不正常例子,通常你需要将你的第一个估计值乘以 3 倍。从长远来看,这会节省你的时间。
这并不意味着你不应该从小数字起步。后文会讲到的。
对于任何新的数据集,你的目标都应该是成为主题专家。检查分布,找出不同类型的特征,异常值的位置,和异常值的原因。如果你不能讲述出你正在处理的数据的故事,如何能指望你的模型可以呢?
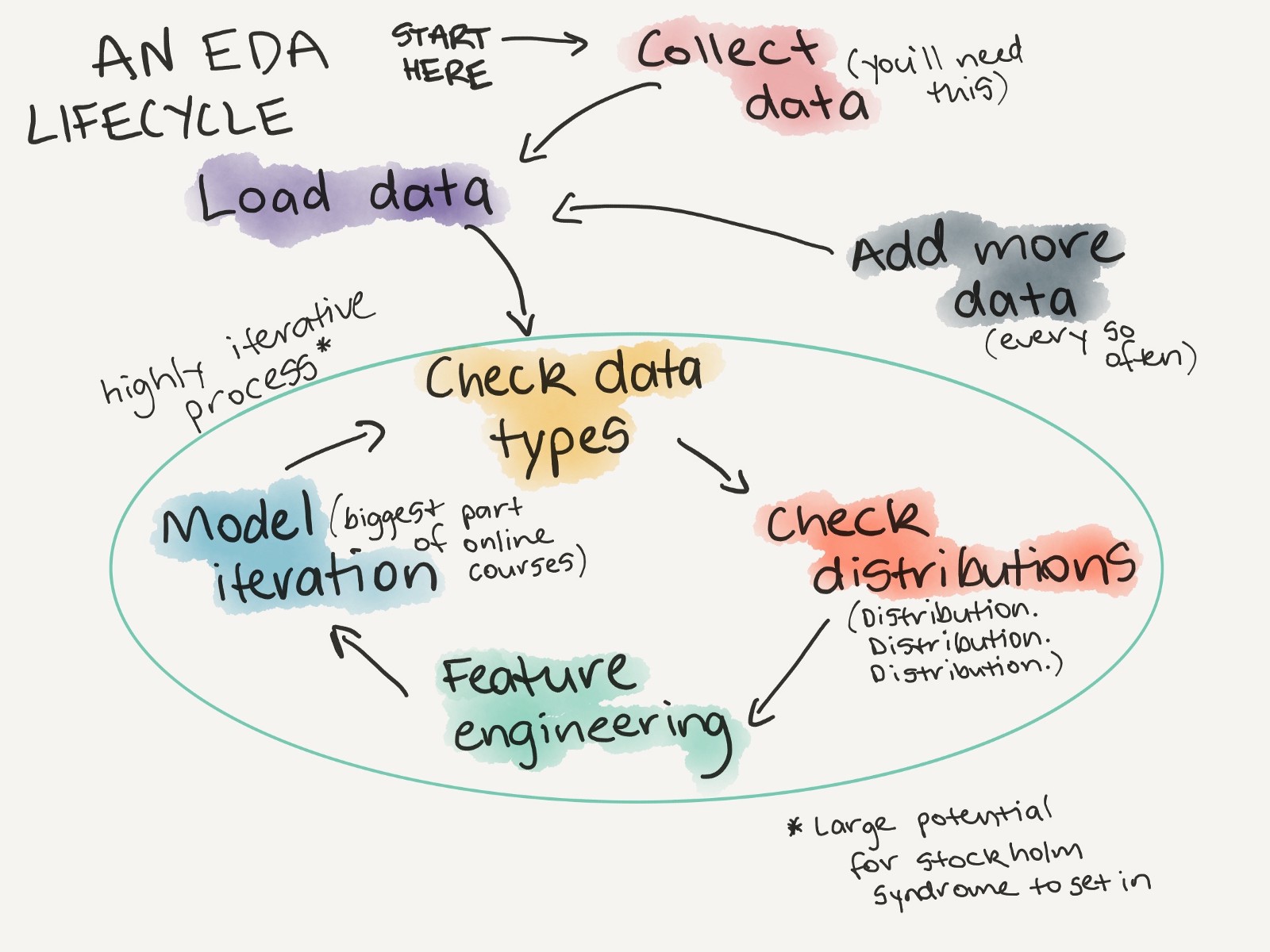
一个探索性数据分析生命周期的例子(每次遇到新数据集时需要做什么)。
更多相关内容,请参阅 A Gentle Introduction to Exploratory Data Analysis。
我遇到的大多数主要障碍不是技术上的,而是交流上的。当然,总是有技术上的挑战,但是解决技术难题是工程师的职责。
永远不要低估沟通的重要性,无论是内部的还是外部的。没有什么比解决一个错误的技术难题更糟糕的了。
这是怎么发生的呢?
从外部来看,这是客户想要的东西和我们不能提供但是机器学习可以提供的东西之间的不匹配。
从内部来看,因为很多人身兼数职,所以很难确保每个人都有相同的目标。
这些难题并不是独一无二的。机器学习似乎很神奇。在某些情况下确实如此。但在这种情况下并不能,承认这一点很重要。
如何解决?
定期接触最基础的部分。你的客户是否了解你可以提供的服务内容? 你了解你的客户的问题吗? 他们是否了解机器学习可以提供什么以及不能提供什么? 什么是可以用来交流你的成果的有用方式?
内部如何协调?
你可以根据预计解决问题的软件工具的数量来判断内部沟通的难度。 Asana,Jira,Trello,Slack,Basecamp,Monday,微软团队都是这么做的。
我发现最有效的方法之一是在一天结束时在相关的项目频道中进行简单的消息更新。
e.g.
更新:
下一步:
这是完美的吗?不。但似乎有效。这个方法给了我一个机会来回顾所做的工作以及预期目标,这意味着如果我的工作看上去不成功,可能会受到批评。
不管你是一名多么优秀的工程师,你维护和获得新业务的能力都与你沟通业务的能力以及业务带来的好处是相关的。
我们有一个自然语言问题: 将文本分类到不同的类别。 目标是将用户发送到服务端的文本自动分类为两个类别之一。 如果模型对预测没有信心,就将文本传递给人工分类器。 每天的工作量约为 1000-3000 个,不是太多也不是太少。
BERT 一直都是这一年最受欢迎的模型。 但是,如果没有谷歌规模的计算,用 BERT 训练模型来做我们需要的东西在投入生产之前需要太多的处理。
因此,我们使用了另一种方法 ULMFiT ,这种方法不是最先进的,但仍然产生了足够的结果,并且更容易使用。
实现出一些有用的东西比停在你想要追求完美的东西上更有价值。
在将机器学习付诸实践时存在两个坑。从课程工作到项目工作的差距,以及从笔记本中的模型到生产中的模型(模型部署)的差距。
在网上搜索机器学习课程会返回大量的结果。我用过其中的许多来创建我自己的AI硕士学位 https://bit.ly/AIMastersDegree。
但即使在我完成了许多最好的课程之后,当我开始成为一名机器学习工程师时,我的技能也是建立在课程结构的主干之上的。而现实中,项目并不是已经结构化的。
我缺乏具体的知识,而这些是无法在课程中教授的。如何质疑数据,哪些需要被研究和利用。
具体知识无法在课程中教授但可以实际学习到的技能。
解决方法是什么?
我很幸运能和澳大利亚最优秀的人才在一起。但我也愿意学习,愿意犯错。当然,犯错不是目的,但为了正确,你必须弄清楚哪里出了问题。
如果你正在通过课程学习机器,那么继续学习这门课程 , 但是需要通过自己的项目把你正在学习的内容付诸实践,从而掌握具体的知识。
如何部署?
我在这方面还是很弱。但我确实注意到了一种趋势。机器学习工程和软件工程正在融合。有了诸如 Seldon, Kubeflow 和 Kubernetes 这样的服务,机器学习很快就会成为另一个组成部分。
在 Jupyter 笔记本上建立一个模型是一回事,但是你如何使这个模型能被成千上万甚至数百万人使用呢?从 Cloud Native events 最近的会谈 来看,除了大公司之外,很少有人知道如何做到这一点。
我们有个规矩:20% 的时间。这意味着我们可以将 20% 的时间花在学习机器学习领域中的事物上,有很多东西可以学。
事实不止一次证明这是无价的。使用 ULMFiT 而不是 BERT 就是由于这 20% 的时间。
20% 的时间意味着 80% 的时间将花在核心项目上。
80% 时间用在核心产品(机器学习专业服务)。
20% 时间用于核心产品相关的新产品。
我们并不总是像这样划分,但这是一个很好的目标。
如果你现在的业务优势是在所做的领域上做到最好,那么未来的业务就取决于你在所做的业务上继续做到最好。这意味着需要不断学习。
这是一个粗略的度量。但是研究任一数据集或现象,你很快就会发现它无处不在。这是齐普夫定律(Zipf’s law,https://en.wikipedia.org/wiki/Zipf%27s_law) 或普莱斯定律 (Price’s law,https://en.wikipedia.org/wiki/Price%27s_model) ,其中之一,它们都和我的数据相似。普莱斯定律指出,一半的出版物来自于其所有作者数量的平方根数量的作者。
换句话说,在每年提交的数千份报告中,可能有 10 份开创性的论文。在这 10 篇开创性的论文中,5 篇可能来自同一个研究所或个人。
重点是什么呢?
你没办法跟上每一个新的突破。所以更好的原则是,掌握基本原则,打好坚实的基础,并加以应用。这些是经得起时间考验的。新的突破也是参考了原始的突破。
但接下来是研究还是开发的问题。
你可以通过成为自己最大的怀疑论者来处理研究还是开发的问题。
研究还是开发的问题是在尝试新事物和重新应用已经奏效的东西之间的两难境地。
开发 很容易去运行你已经使用过的模型,并获得一个高精度的数字,然后将其作为新的基准报告给团队。但是如果你得到了一个好的结果,记得检查你的工作,反复多次,让你的团队也做同样的事情。你是工程师兼科学家是有原因的。
研究 20% 的时间可以帮助解决这个问题。但是 70/20/10 的时间分配可以做得更好。比如把 70% 的时间花在核心产品上, 20% 的时间花在建立核心产品的基础上, 10% 的时间花在试验上,试验可能不会(极有可能不会)奏效的事情。
我从来没有在我的工作中实践过这一点,但我正在朝这个方向努力。
解决简单问题,很有助于理解新概念。建立小的东西,它可以是数据的一个小的子集,也可以是不相关的数据集。
在一个小团队中,诀窍是先建立些有效的东西,然后快速迭代。
罗恩教我的这个方法。 如果你被问题困住,坐着盯着代码可能会解决问题,可能不会。相反,你应该和你的队友用言语来交流,假装他们是你的橡皮鸭。
“罗恩,我正在尝试遍历这个数组,并在跟踪状态的同时循环另一个数组并跟踪状态,然后我想将这些状态组合成一个元组列表。”
“循环中的循环? 你为什么不把它矢量化呢?“
“我能这样做吗?”
“让我们试试看。”
这又回到了机器学习工程与软件工程融合的问题上。
除非你的数据问题非常具体,否则很多主要的问题是非常相似的,比如 分类、回归、时间序列预测、推荐等。
像谷歌和微软的 AutoML 等等这样的服务,正在使世界级的机器学习对每一个人都可用,都能够上传数据集并选择目标变量。虽然现在还处于早期阶段,但他们的势头正在迅速增强。
在开发人员方面,你有像 fast.ai 这样的库,它们可以在几行代码中提供最先进的模型,以及各种模型动画(一组预先构建的模型),像 PyTorch hub 和 TensorFlow hub 那样相同的功能。
这意味着什么?
了解数据科学和机器学习的基本原理仍然是必要的。 但是知道如何将它们应用到你的问题中更有价值。
现在如果你的模型不是最先进的,也应该是接近的。
对于我处理的客户端问题,我们都是先写代码。所有的机器学习和数据科学代码都是 Python 编写的。我有时会通过阅读论文并复现它来涉猎数学,但 99.9% 的情况下,现有框架已经涵盖了数学。
这并不是说数学没有必要,毕竟机器学习和深度学习都是应用数学的两种形式。
了解最基本的矩阵操作,一些线性代数和微积分,特别是链式法则 ,足以成为一个实践者。
记住,我的目标不是发明一种新的机器学习算法,而是向客户展示机器学习对他们的业务有(或没有)潜在的好处。
附注:在写这篇文章的过程中,fast.ai 刚刚发布了一门新的课程,《从基础开始深度学习》(Deep Learning from the Foundations ,它将从头开始学习深度学习的数学和代码。它是为像我这样熟悉应用深度学习和机器学习但缺乏数学背景的人而设计的。为了解决这个问题,我正在研究这本书,并且立即把它添加到我最喜欢的机器学习和数据科学资源的列表 中。有了坚实的基础,你就可以构建自己的最先进的技术,而不是在以前的基础上进行迭代更新。
这是一定的。随着软件工程与机器学习工程的融合,其发展趋势也越来越明显。
但还是你已经学过的内容。
那么什么会保持不变?
框架会改变,库会改变,但是底层的统计,概率,数学,这些东西没有过期日期(甚至是一个更好的时机来学习新的 fast.ai 课程)。
最大的挑战仍然是:如何应用它们。
本可以写更多,但 12 点就足够了。
在 Max Kelsen 工作是我做过的最好的工作。工作很有趣,同事更好。我学到了很多。
离开并不是一个容易的选择,但是我决定用我所学到的来检验我自己,我正致力于健康、科技和艺术的交叉领域上。
对我的文章感兴趣的朋友,可以关注我的微信公众号(ID:PyDataLab),接收我的更新通知。
